从“用户信息”到“向量表示”:一篇把用户特征转 成 Embedding 的完整实战指南
开篇:为什么一定要把用户特征变成向量?
在推荐 / 广告 / 搜索这类场景里,我们最常做的一件事就是:
“这个用户 u,会不会喜欢这个内容/商品 i ?”
要让模型回答这个问题,就需要把 “用户” 和 “内容” 都变成模型可处理的形式。
对于深度模型来说,最顺手的形态就是 定长的实数向量,也就是我们常说的 embedding 向量。
对用户来说,user embedding 可以理解为:
“这个人在兴趣空间里的坐标”
对内容来说,item embedding 可以理解为:
“这个内容在语义/风格空间里的坐标”
然后模型就可以用各种数学操作(点积、拼接 + MLP 等)去判断:
“在这个空间里,这个用户和这条内容是不是‘靠近’?”
这篇文章要解决的问题非常具体:
给你一堆原始的、碎片化的用户特征(如性别、城市、最近一次听歌时间、最近听了多少首、最近听过的歌列表……)
如何一步步把它们变成一条用户 embedding 向量?
下面我们会分阶段来讲:
- 什么是 embedding?为什么要这么干?
- 用户特征都长什么样,先分类;
- 单个特征:从文字/枚举/时间 → 数值 / 小 embedding;
- 把多个特征融合成一个用户向量(短期 + 长期兴趣);
- 这些 embedding 是怎么“学”出来的;
- 一个完整的音乐推荐例子从头走到尾;
- 常见坑和经验小结。
Embedding 是什么?为什么它是“用户向量”的核心?
专业一点的定义
从数学上讲,embedding 就是一个映射:
$f: \text{对象空间} \rightarrow \mathbb{R}^d$
把某种对象(用户、物品、类别、词语……)映射到一个 d 维实数空间 中的向量:
- 每个用户 → 一个 d 维向量
- 每个内容 → 一个 d 维向量
- 每个类别/标签 → 一个 d 维向量
并且这个映射有个重要性质:
在这个向量空间里,“相似的对象”彼此靠近,“不相似的对象”彼此远离。
例如:
- 两个都爱听摇滚的用户,user embedding 会相近;
- 两首风格接近的歌曲,song embedding 会相近。
通俗一点的理解
你可以把 embedding 想象成一张 高维“性格雷达图”:
- 对用户 embedding 来说:
- 第 1 维:偏不偏爱体育;
- 第 2 维:偏不偏爱游戏;
- 第 3 维:偏不偏爱短视频;
- ……(实际上不会这么直接解释,但可以这样想象)
一条 embedding 向量,就是:
“这个在多维兴趣轴上的一个点”。
当我们对用户和内容都这样做之后,就可以:
- 用 点积 / 余弦相似度 来衡量 “喜不喜欢”;
- 用简单几层神经网络就把问题变成 “向量 → 分数”的映射。
用户特征长什么样?先把“原料”分分类
在真正“转成 embedding”之前,先把常见的用户特征按类型分一下类。
这一步很重要,因为 不同类型的特征,处理方式完全不同。
枚举类 / 类别类特征
典型例子:
- 性别:
"男" / "女" / "未知" - 城市:
"北京" / "上海" / ... - 设备类型:
"android" / "ios" / "pc" - 会员等级:
"普通" / "黄金" / "白金"
特点:
- 取值是离散的、有限套枚举;
- 本身没有大小关系(“北京”不比“上海”大)。
数值类特征
典型例子:
- 年龄:
23 - 最近 1 小时内听歌的次数:
17 - 最近 7 天登录天数:
5 - 用户账号注册天数:
365
特点:
- 有自然的大小 / 数值关系;
- 常需要做归一化、log 等处理。
时间类特征
典型例子:
- 最近一次听歌时间:
"2026-01-12 10:30:00" - 当前请求时间:
"2026-01-12 21:05:00"
这些原本是字符串,需要拆解成多种数值:
- 距今多久(秒 / 分钟 / 小时);
- 所在小时(0~23,是否晚上);
- 是周几(工作日 or 周末)……
序列类特征(行为序列)
典型例子:
- 最近听过的 20 首歌的 ID 列表;
- 最近浏览过的 50 个商品;
- 最近观看的视频序列。
特点:
- 不是一个值,而是一个 有顺序的列表;
- 能很好表达“短期兴趣”和“行为轨迹”。
文本类特征
不一定经常用到用户侧,但也存在:
- 用户签名 / 简介;
- 自填职业 / 标签;
- 搜索查询词。
这些一般需要 NLP 模型,将句子 → 向量。
单个特征:从“文字/枚举”到“数值/小 embedding”
这一节我们只关注 “一列特征”,问的问题是:
“这一列的文字 / 枚举 / 时间,怎么变成数值形式?”
后面再讲“多列特征融合成用户 embedding”。
类别特征:性别、城市、设备…怎么编码?
步骤 1:先做 ID 映射(Label Encoding)
例如城市:
1 | "北京" → 0 |
性别:
1 | "男" → 0 |
这一步只是把字符串变成整数标号,方便后面作为索引。
步骤 2:用 embedding 表把离散取值变成向量
对每个类别特征,我们建一张 embedding 表,比如城市:
比如 d_city = 8:
- 北京 (id=0) →
[0.12, -0.3, 0.05, ...] - 上海 (id=1) →
[0.08, 0.2, -0.1, ...] - 广州 (id=2) →
[...]
调用方式就像:
1 | city_emb = city_emb_table[city_id] |
专业表述:
对高基数类别特征,通常使用 embedding lookup 将类别 ID 映射到低维稠密向量空间,以增强表达能力并减小维度。
通俗理解:
给每个城市画一小段“属性向量”,这些向量是训练出来的,它会捕捉到例如:
- 一线城市之间会更相似;
- 同省城市可能更接近;
- 不同消费水平城市的 embedding 也会分布不同。
数值特征:听歌次数、年龄……怎么处理?
简单方式:直接归一化
例子:最近一小时听歌次数 cnt_1h = 17,假设认为 >50 都算“很多”。
可以做:
1 | cnt_norm = min(cnt_1h / 50.0, 1.0) |
或者用 log:
1 | cnt_log = log(1 + cnt_1h) |
此时我们得到一个数值特征,可以直接当作模型输入的一维浮点数。
稍复杂的方式:数值 → 区间 → embedding
有时我们希望模型更灵活处理数值,也会:
- 把数值离散成区间(bucket):
- 0–5 首:bucket 0
- 6–10 首:bucket 1
- 11–20 首:bucket 2
- 20+ 首:bucket 3
- 然后给 bucket_id 建 embedding 表:
1 | cnt_bucket → bucket_id → bucket_emb (R^d) |
专业表述:
对具有非线性影响的数值特征,可通过分桶 + embedding 的方式增强模型对不同区间的敏感度。
通俗理解:
有时“听 0~5 首”和“听 20 首以上”的意义完全不同,简单当作线性数值不够灵活;
把它们分成“档位”,对每个档位学一个小向量,模型更容易学到规律。
时间特征:最近一次听歌时间怎么变?
假设有字段:last_play_time = "2026-01-12 10:30:00"
可以拆成几种有用的数值特征:
- 距当前时间的间隔(秒/分/小时):
1 | delta_t_hours = (now - last_play_time) / 3600 |
- 小时(0~23):表达 “早上 / 中午 / 晚上 / 深夜” 信息
1 | hour_of_day = 10 |
- 星期几(0~6):表达 “工作日 / 周末” 信息
- 是否节假日 / 特殊日期(布尔)
处理方式:
delta_t→ 归一化数值特征hour_of_day→ 作为一个小类别特征,建小时 embedding 表(24 个取值,embedding 维度可以很小)weekday→ 类别特征同理
通俗比喻:
模型不关心你具体是哪天哪年哪月那分钟,但它很在意:
- “很久没听歌了” vs “刚刚听过”;
- “半夜在听” vs “上班时间在听”;
- “工作日” vs “周末”。
序列特征:最近听过的 N 首歌
假设有序列:
1 | recent_songs = [s1, s2, s3, ..., sN] |
每首歌都有自己的 content embedding:
1 | song_emb_i = emb_song(s_i) |
那我们可以先对每首歌取 embedding,然后做一个“聚合”(pooling):
- 简单平均:
1 | seq_emb = (song_emb_1 + song_emb_2 + ... + song_emb_N) / N |
- 加权平均:(越新的权重越高)
1 | weight_i = f(时间间隔) # 比如用指数衰减 |
- 更高级:RNN / Transformer(下面会再提)
对于“用户短期兴趣向量”,常见做法是:
对最近的行为序列 embedding 做一个聚合,得到一个 short_term_user_emb。
文本特征:用户签名 / 搜索词
不展开讲太深,只给个直觉:
- 文本 → 分词 / token;
- 每个 token → token embedding;
- 再用平均 / CNN / RNN / Transformer 聚合;
- 得到一个句子级 embedding,作为一个额外特征。
例如:用户简介 "喜欢二次元和游戏"
→ 文本 embedding:user_profile_emb,也是一条向量。
把多个特征融合成“用户 embedding”
到目前为止,我们知道了如何把 单个特征列 变成数值 / 小向量。
接下来要回答最重要的问题:
怎么把这么多不同的特征,合成一条最终的 user embedding 向量?
大致会分两层:
- 单次行为级别的向量:
把“这一次请求/这一个 session 的所有特征”做成一个向量; - 长期/整体用户向量:
用多个行为向量 + 历史统计信息,得到“这个用户的长期兴趣向量”。
行为级特征 → 行为 embedding(behavior embedding)
假设我们有这样一条“当前请求”的用户特征:
user_idgendercitydevice_typehour_of_dayrecent_cnt_1h(最近1小时听歌次数)recent_song_seq(最近10首歌的序列)
前面我们已经知道如何把它们分别变成数值/向量:
- user_id_emb(比如 64 维)
- gender_emb(比如 4 维)
- city_emb(比如 8 维)
- device_emb(比如 8 维)
- hour_emb(比如 4 维)
- recent_cnt_1h_norm(1 维数值)
- short_term_seq_emb(对最近10首歌的 song_emb 做平均/attention 得到,32~64 维)
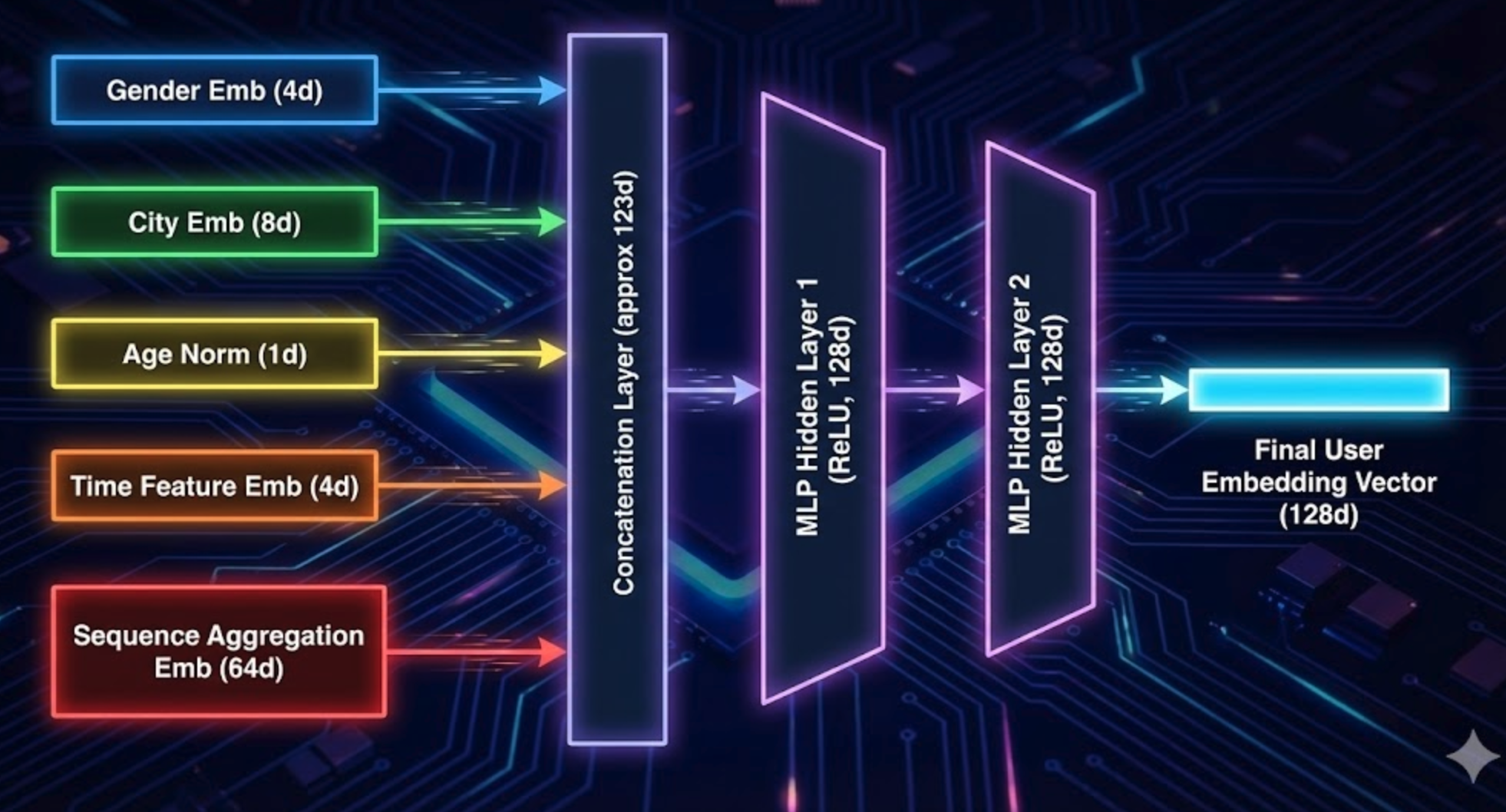
第一步:拼接成一个大向量
1 | x = concat( |
假设拼接完的 x 是 200 维左右。
第二步:用一层或多层 MLP 压缩 + 提取语义
1 | h1 = ReLU(W1 * x + b1) # 比如 128 维 |
专业表述:
将多个特征 embedding 与数值特征拼接后,通过多层感知机(MLP)进行非线性变换,可以获得更抽象、更高阶的行为表示。
通俗理解:
你把“性别、城市、设备、时间、短期行为”等这些信息丢进一个“搅拌机”(MLP),它会学会:
- 晚上在地铁上听歌的人更偏向哪些风格;
- 某些城市 + 某种设备的用户,更偏爱某类内容;
最终吐出来一条向量,就是 “本次行为/当前状态”的高维描述。
很多模型会把这条 behavior_emb 直接当作当前的 user_emb 使用,尤其在 session-based 推荐中。
长期兴趣:用历史行为序列构建 user embedding
上面是 “当前行为+短期历史” 的表示。
有时我们还想有一个 长期稳定兴趣 的 user embedding:
- 统计过去很长时间的行为(如近 30 天、近 3 个月);
- 得到一个长期的 user embedding,表示“这个人的整体口味”。
常见做法:
方法 1:历史内容 embedding 平均
- 对用户过去 N 条行为,每条行为都能得到一个行为 embedding(如
behavior_emb_t); - 对这些 embedding 做平均 / 加权平均:
1 | user_long_emb = Σ(weight_t * behavior_emb_t) / Σ(weight_t) |
- 权重可以根据时间衰减(越近越重);
- 简单但非常常用。
方法 2:序列模型(RNN / Transformer)
把过去的行为 embedding 当作一个序列:
1 | [h_t1, h_t2, ..., h_tN] # 每个 h_ti 是一次行为 embedding |
丢给一个序列模型,比如:
- GRU / LSTM
- Transformer / 自注意力网络
最后取:
- 最后一个 hidden state;或者
- 对所有 hidden state 做 attention pooling
得到长期 user_emb。
通俗比喻:
方法1是“简单算平均成绩”,
方法2则更像“看整段历史的走势和结构”。
最终 user embedding
实战中,经常把 长期 + 短期 结合:
1 | user_emb_final = concat(user_long_emb, user_short_emb) |
这样:
- 长期 embedding:代表“这个人整体是什么类型”;
- 短期 embedding:代表“最近一段时间特别关心什么”。
这些 embedding 是怎么“学”出来的?
一个关键点:所有这些 embedding 和 MLP 权重,最初都是随机的,是通过训练“学出来”的,不是拍脑袋写死的。
训练的监督信号:点击 / 播放 / 下单 / 停留时间
在推荐/广告里,最常见的训练目标是:
预测:用户在看到某个内容后,会不会发生某种行为(点击、播放完、下单……)
每条训练样本大概长这样:
1 | (user_features, item_features, label) |
- user_features:用上面讲的方法转为 user_emb 相关特征;
- item_features:也会转为 item_emb;
- label:1 表示点了 / 看了,0 表示没点 / 没看。
模型输出一个分数 ŷ,表示预测的点击概率,
我们用真实 label y 和 ŷ 算 loss(比如交叉熵),通过反向传播更新 所有参数:
- 用户特征的 embedding 表;
- 内容特征的 embedding 表;
- MLP 的权重;
- 序列模型的权重……
通俗理解:
模型每天在“看海量用户行为日志,玩真心话大冒险”。
每答错一题(预测点但用户没点,或没预测点但用户点了),
就反思一下,把 embedding 和网络参数微调一点点。
经过大量这样的训练,embedding 里就隐含地学到了“谁像谁、谁喜欢什么”。
一个完整的小例子:音乐 APP 的用户 embedding
我们用一个具体例子,把前面所有环节串起来。
假设有的用户特征
某音乐 App 的一条“当前请求”用户特征:
user_id = 123456gender = "男"city = "上海"device = "android"age = 26last_play_time = "2026-01-12 10:30:00"recent_cnt_1h = 17(最近1小时听了17首)recent_songs = [s_1, s_2, ..., s_10](最近10首歌ID)user_profile = "喜欢周杰伦和动漫歌曲"(用户签名,可选)
我们要把这些东西,变成一条最终 user_emb_final。
单个特征怎么变成数值/向量?
gender- “男” → id=0 →
gender_emb(R^4)
- “男” → id=0 →
city- “上海” → city_id=1 →
city_emb(R^8)
- “上海” → city_id=1 →
device- “android” → dev_id=0 →
device_emb(R^8)
- “android” → dev_id=0 →
age- 26 →
age_norm = 26 / 80(大致归一化)
- 26 →
last_play_time- 计算距离当前时间
delta_t_hours,比如 1.5 小时 delta_t_norm = log(1 + 1.5)/ log(1 + max)hour_of_day= 10 →hour_emb(R^4)
- 计算距离当前时间
recent_cnt_1h- 17 →
cnt_norm = min(17/50, 1)→ ≈0.34
- 17 →
recent_songs- 每首歌 s_i 有一个
song_emb_i(R^64) - 做加权平均(越新的权重越大),得到
short_term_seq_emb(R^64)
- 每首歌 s_i 有一个
user_profile(可选)- 文本 → 分词 → 词 embedding → 平均 →
profile_emb(R^32)
- 文本 → 分词 → 词 embedding → 平均 →
拼接 + MLP → 当前状态的行为 embedding
拼接:
1 | x = concat( |
MLP:
1 | h1 = ReLU(W1 * x + b1) # 128 维 |
长期兴趣 embedding
对过去 30 天的行为序列:
- 每个行为都有一个
behavior_emb_t(结构和上面类似,或简化版); - 用简单平均 / 加权平均 / RNN 等得到
user_long_emb(R^128)。
最终 user embedding
把长期 + 短期拼在一起,再轻微融合:
1 | z = concat(user_long_emb, user_short_emb) # 256 维 |
user_emb_final 就是你在整个系统里给 “用户 123456” 的最终向量表示。
- 打分时:
score = f(user_emb_final, song_emb_candidate, other_features) - 做 “相似用户” 分析时:
用 user_emb 的距离比较; - 做“社区 embedding”时:
直接对一群用户的 user_emb 做平均即可。
常见坑 & 经验提示
不要把“类别 ID 当数值”直接喂线性模型
例如 city_id 0、1、2 ……
不能直接当作 “0.0, 1.0, 2.0” 的数值给线性模型,否则模型会认为有 “大小关系”和“线性距离”,是错误的语义。
正确做法:
→ 做 one-hot 或 embedding lookup。
embedding 维度不要盲目开太大
- 类别特别多(上百万用户 ID / 内容 ID),维度太大容易过拟合 + 耗内存;
- 经验:
- 小词表/小类别(几十 / 几百种):8~16 维足够;
- 大词表(几万 / 几十万):16~64 常见;
- 巨大 ID(上百万):可考虑 64~128,但要搭配正则、裁剪等。
一个简单 thumb rule(只是参考,不是铁律):
embedding_dim ≈ min(50, 6 * (类别数)^(1/4))
未登录用户 / 新用户(cold start)怎么办?
- 没有 user_id 时,就无法使用用户ID embedding;
- 这种情况下更依赖:
- 当前 session 的行为序列(短期兴趣);
- 设备 / 城市 / 渠道等上下文特征;
- 可以单独训练一个 “session-based” 模型,仅用最近行为序列构造 user embedding。
未出现过的新取值(新城市、新设备)
- 对于 embedding 表中没见过的类别,可以:
- 映射到一个特殊 ID:``(unknown);
- `` 也有自己的 embedding,会在训练中学习“未知值的一般行为”。
hash vs embedding 的区别别搞混
- hash:只是给东西一个“桶号”,本身不负责表达语义;
- embedding:通过训练学习出“语义坐标”。
在实践中,你可以:
- 先用 hash 把原始字符串变成整数 ID;
- 再用 embedding 表把整数 ID → 向量。
总结:从用户特征到 embedding 的标准路线
我们最后把整个流程再用一段话总结一下:
- 识别特征类型
- 枚举类 → ID 编码 + embedding 表
- 数值类 → 归一化 / 分桶 + embedding
- 时间类 → 拆成间隔、小时、星期几等,再按上面处理
- 序列类 → 用 item embedding 聚合成序列 embedding
- 文本类 → NLP 模型 → 文本 embedding
- 拼接成一个大特征向量
把所有这些“单特征 embedding + 数值特征”拼接起来。 - 用 MLP 提炼成一个行为级 embedding
MLP 负责“混合特征、抽取模式”,输出行为 embedding。 - 用历史行为序列构建长期 user embedding
对多次行为 embedding 做平均 / 加权 / RNN/Transformer,得到长期兴趣向量。 - 长期 + 短期 融合成最终 user embedding
在推荐 / 广告 / 搜索中,跟 item embedding 结合做打分。 - 所有 embedding 都是在训练中自动学出来的
通过点击/观看/转化等监督信号,不断更新 embedding 和网络。
 wechat
wechat alipay
alipay